Algorithm Revisions
Algorithm Revisions
What have we been working on? Besides a lot of research projects, we have been improving Jigsaw in a few important ways. Perhaps the most important new feature is revision numbers for algorithms. The revision numbers tell us whether there have been any changes to the algorithm, and what kinds of changes they were.
It is a very simple system with 3 digits in the format of X.Y.Z. All versions start at 1.0.0. Changes that could affect the data that Jigsaw extracts (e.g., changing an ICD-10-CM code) are recorded by increasing the first digit (X). Changes to the metadata that Jigsaw outputs, but that don’t affect the actual data (e.g., algorithm tags used to classify an algorithm) are reported using the second digit (Y). And cosmetic changes (e.g., changes to the text description) are captured with a change to the third digit (Z). And, of course, users can access all prior versions.
We considered some of the more esoteric features of version-control systems, but they didn’t seem very useful. For the most part, algorithms follow a very linear path, with minor revisions over time as codes get updated, and descriptive texts is modified. We already have the ability to duplicate algorithms, so it isn’t a problem to take a previous version and make it a new algorithm. But, if the need arises, we can add additional version-control features.
As far as we know, there is nothing else out there that allows researchers to save their algorithms in unambiguous language and keep track of them as they change over time. This is particularly helpful when someone has to revisit a project that was completed several years ago. But most importantly, this feature can help users keep track of the version they used when we make our algorithm repository public. We are not quite there yet, but you can be sure that there will be a blog post as soon as we are.
Let’s Look at an Example
To make some of this this a little more tangible for readers, below in Figure 1 is a random slice of algorithms from a study we are working on using SEER-Medicare data. You can see the revision numbers after each algorithm name (all version 1.0.0).
Figure 1: Selection of algorithms
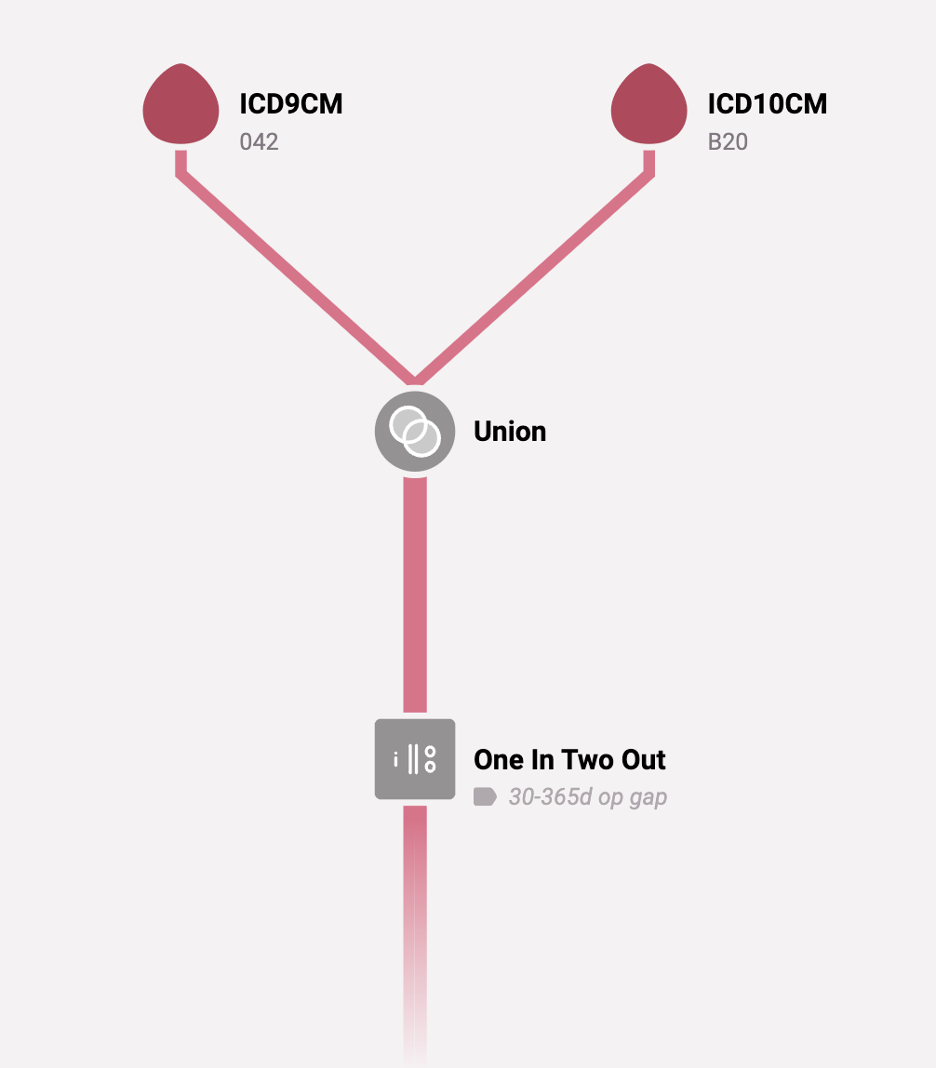
And, as a reminder for people who don’t know how we work, Figure 2 below shows the graphical depiction of the NCI Comorbidity Index HIV algorithm. We intentionally picked this one because it is very simple to display. It looks for ICD-9-CM code 042 or ICD-10-CM code B20. It requires at least 1 inpatient claim, or at least 2 outpatient claims at least 30 days apart, but within 365 days. It returns the initial outpatient event or the discharge date from the inpatient claim, depending on which criterion was met.
Figure 2: HIV Algorithm Diagram
And for those of you who wonder how we store that information, Figure 3 below shows the JSON representation of the same algorithm. From the JSON, the underlying ConceptQL library can generate SQL in a variety of dialects (including PostgreSQL which our default) for a variety of data models (including the Generalized Data Model, which is our default). Unfortunately, the SQL that gets created from the JSON would take up too many pages for me to show. But it is available for users to copy and paste if they want to run something manually, or adapt it for other purposes.
Figure 3: JSON Algorithm Representation
